Apple Silicon(M1 / M2)MacのGPU(Metal / mps)を使ってStable DiffusionのLoRAを学習させる。
環境構築
インストール
Miniforgeとかは入っているものとする。
conda create -n kohya_ss python==3.10.9
conda activate kohya_ss
# conda install -c apple tensorflow-deps 今はいらないかも…
# LoRAの学習用コードをダウンロード
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python ./setup/setup_linux.py --platform-requirements-file=requirements_macos_arm64.txt
pip install huggingface_hub==0.25.0 # huggingface_hubのcached_downloadに関するエラーが出るのでバージョンを下げる古いバージョンのインストール手順
仮想環境に入って以下のように環境構築を行う。
(ここでは、PythonバージョンはPython 3.10.6で実施した)
conda create -n kohya_ss python==3.10.9
conda activate kohya_ss
python ./setup/setup_linux.py --platform-requirements-file=requirements_macos_arm64.txt
# metal用のpytorchをインストール
pip3 install torch torchvision
# metal用のtensorflowをインストール
conda install -c apple tensorflow-deps # 今はいらないかも…
pip3 install tensorflow-macos tensorflow-metal tensorboard
# diffusersのインストール
pip install diffusers
# LoRAの学習用コードをダウンロード
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
# requirements.txt の tensorflow, tensorboard はコメントアウトする
pip install -r requirements.txtAcceleratorの設定
一度設定すれば~/.cache/huggingface/accelerate/default_config.yamlに記録されているので2回目以降は必要ない。
# acceleratorの設定をする
accelerate config
#以下のように答える
--------------------------------------------------------------------------------
In which compute environment are you running?
This machine
--------------------------------------------------------------------------------
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]:NO
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
--------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
no
accelerate configuration saved at ~/.cache/huggingface/accelerate/default_config.yaml 学習用のデータを準備
まずは、学習させたい画像を用意し、Stable Diffusion Web UIにDataset Tag Editorを導入して画像のキャプションテキストを作成する。(詳細はこの記事を参照)
画像とキャプションのtxtファイルが入ったフォルダが用意できたら、kohya_ss/dataset/imagesにフォルダを移動する。この時、images以下に配置するフォルダ名は20_dogsのように「
繰り返し回数_トリガーワード」のような命名規則で作成する。
古いバージョンのデータセットの準備方法
詳しくは、配布元の説明を参照すること。
作成場所はどこでも良いが、配布元の説明にあるように、ディレクトリ構造と命名規則は守る。
画像のファイル名や種類は適当にする。
- 学習用のディレクトリを作成する(作成場所・名前は自由/今回はtrainとした)
- 学習用のディレクトリ配下に学習画像を格納するディレクトリを作る
名前は、「<繰り返し回数>_<学習させる概念を表すワード> <学習させる概念を包括するワード>」とする
例えば、自分の飼っている犬の画像をpochiという単語に学習させるなら、「20_pochi dog」のようにする - 学習データを格納するディレクトリ配下に学習させる画像を入れる(画像のファイル名や種類は適当で良い)
- 必要であれば正規化用のディレクトリを作成する(作成場所・名前は自由/今回はregとした)
正規化画像があると、例えばpochiを学習させる際にdogがpochiに影響されるのを防いでくれるらしい - 正規化用のディレクトリ配下に正規化画像を格納するディレクトリを作る
名前は、「<繰り返し回数>_<学習させる概念を包括するワード>」とする
例えば、自分の買っている犬の画像をpochiという単語に学習させるなら、「20_dog」のようにする - 学習元のモデルに<学習させる概念を包括するワード>(今回はdog)をプロンプトに入力して、正規化画像を生成する
- 正規化画像を格納するディレクトリ配下に正規化画像を入れる(画像のファイル名や種類は適当で良い)
- LoRAの出力用のディレクトリを作成する(作成場所・名前は自由/今回はoutputsとした)
.
├── train
│ └── 20_pochi dog
│ ├── AAA1.jpg
│ ├── AAA2.jpg
│ ├── AAA3.jpg
├── reg
│ └── 20_dog
│ ├── BBB1.png
│ ├── BBB2.png
│ ├── BBB3.png
│ ├── BBB4.png
│ ├── BBB5.png
└── outputs学習の実行
GUIの起動は以下のようにする。
python kohya_gui.py Lora>Trainingを選択し、以下の設定を変更する。
- Model>Image folderに先ほど配置した学習画像が入ったフォルダの親を指定する
ここでは、kohya_ss/dataset/imagesを指定すれば良い - Folders>Output directory for trained modelにLoRA モデルの保存先を設定する
ここでは、kohya_ss/outputs/20_dogsとした
また、MacでGPUを使用する場合は以下のように設定しなければ動かない。
- Accelerate launch>Mixed precisionをnoに設定する。(その半精度以下のオプションは選択しない;fp16,bf16,fp8みたいなやつはチェックしない)
- Advanced>Weights>CrossAttentionのxformersをnoneに設定する。
- Parameters>OptimizerをAdamWに設定する。(AdamW_8bitのような量子化を使用するものでなければ何でも良い)
その他の項目は適当に設定すれば良い。
以下を確認して設定するか、別の解説記事を参照してください。
筆者の設定の詳細
以下の設定をconfigのような名前で保存し、Configurationの部分で作成したconfigファイルを読み込めば設定がロードできる。
メモリの容量によってはオーバーフロして動かないので、train_batch_sizeとgradient_accumulation_steps(勾配累積)で調整する。例えば、train_batch_size=2でgradient_accumulation_steps=8の場合は実質的にバッチサイズ16のような結果が得られる。
{
"LoRA_type": "Standard",
"LyCORIS_preset": "full",
"adaptive_noise_scale": 0,
"additional_parameters": "",
"async_upload": false,
"block_alphas": "",
"block_dims": "",
"block_lr_zero_threshold": "",
"bucket_no_upscale": true,
"bucket_reso_steps": 64,
"bypass_mode": false,
"cache_latents": true,
"cache_latents_to_disk": false,
"caption_dropout_every_n_epochs": 0,
"caption_dropout_rate": 0,
"caption_extension": ".txt",
"clip_skip": 2,
"color_aug": false,
"constrain": 0,
"conv_alpha": 1,
"conv_block_alphas": "",
"conv_block_dims": "",
"conv_dim": 1,
"dataset_config": "",
"debiased_estimation_loss": false,
"decompose_both": false,
"dim_from_weights": false,
"dora_wd": false,
"down_lr_weight": "",
"dynamo_backend": "no",
"dynamo_mode": "default",
"dynamo_use_dynamic": false,
"dynamo_use_fullgraph": false,
"enable_bucket": true,
"epoch": 8,
"extra_accelerate_launch_args": "",
"factor": -1,
"flip_aug": false,
"fp8_base": false,
"full_bf16": false,
"full_fp16": false,
"gpu_ids": "",
"gradient_accumulation_steps": 8,
"gradient_checkpointing": false,
"huber_c": 0.1,
"huber_schedule": "snr",
"huggingface_path_in_repo": "",
"huggingface_repo_id": "",
"huggingface_repo_type": "",
"huggingface_repo_visibility": "",
"huggingface_token": "",
"ip_noise_gamma": 0,
"ip_noise_gamma_random_strength": false,
"keep_tokens": 0,
"learning_rate": 0.0001,
"log_tracker_config": "",
"log_tracker_name": "",
"log_with": "",
"logging_dir": "",
"loss_type": "l2",
"lr_scheduler": "cosine",
"lr_scheduler_args": "",
"lr_scheduler_num_cycles": 1,
"lr_scheduler_power": 1,
"lr_warmup": 10,
"main_process_port": 0,
"masked_loss": false,
"max_bucket_reso": 2048,
"max_data_loader_n_workers": 0,
"max_grad_norm": 1,
"max_resolution": "512,512",
"max_timestep": 1000,
"max_token_length": 75,
"max_train_epochs": 0,
"max_train_steps": 0,
"mem_eff_attn": false,
"metadata_author": "",
"metadata_description": "",
"metadata_license": "",
"metadata_tags": "",
"metadata_title": "",
"mid_lr_weight": "",
"min_bucket_reso": 256,
"min_snr_gamma": 0,
"min_timestep": 0,
"mixed_precision": "no",
"model_list": "",
"module_dropout": 0,
"multi_gpu": false,
"multires_noise_discount": 0.3,
"multires_noise_iterations": 0,
"network_alpha": 1,
"network_dim": 8,
"network_dropout": 0,
"network_weights": "",
"noise_offset": 0,
"noise_offset_random_strength": false,
"noise_offset_type": "Original",
"num_cpu_threads_per_process": 2,
"num_machines": 1,
"num_processes": 1,
"optimizer": "AdamW",
"optimizer_args": "",
"output_dir": "./outputs/20_dogs",
"output_name": "last",
"persistent_data_loader_workers": false,
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"prior_loss_weight": 1,
"random_crop": false,
"rank_dropout": 0,
"rank_dropout_scale": false,
"reg_data_dir": "",
"rescaled": false,
"resume": "",
"resume_from_huggingface": "",
"sample_every_n_epochs": 0,
"sample_every_n_steps": 10,
"sample_prompts": "dogs",
"sample_sampler": "euler_a",
"save_as_bool": false,
"save_every_n_epochs": 1,
"save_every_n_steps": 20,
"save_last_n_steps": 10,
"save_last_n_steps_state": 0,
"save_model_as": "safetensors",
"save_precision": "float",
"save_state": false,
"save_state_on_train_end": false,
"save_state_to_huggingface": false,
"scale_v_pred_loss_like_noise_pred": false,
"scale_weight_norms": 0,
"sdxl": false,
"sdxl_cache_text_encoder_outputs": false,
"sdxl_no_half_vae": false,
"seed": 0,
"shuffle_caption": false,
"stop_text_encoder_training": 0,
"text_encoder_lr": 0.0001,
"train_batch_size": 2,
"train_data_dir": "./dataset/images",
"train_norm": false,
"train_on_input": true,
"training_comment": "",
"unet_lr": 0.0001,
"unit": 1,
"up_lr_weight": "",
"use_cp": false,
"use_scalar": false,
"use_tucker": false,
"v2": false,
"v_parameterization": false,
"v_pred_like_loss": 0,
"vae": "",
"vae_batch_size": 0,
"wandb_api_key": "",
"wandb_run_name": "",
"weighted_captions": false,
"xformers": "none"
}学習時に途中経過のサンプル画像を生成したい場合
Samplesの部分を設定すれば途中経過を生成してくれるが、Macだと動かないので、kohya_ss/sd-scripts/library/train_util.pyを開いて、以下の箇所を修正する。
cuda_rng_state = torch.cuda.get_rng_state() if torch.cuda.is_available() else Noneをcuda_rng_state = torch.get_rng_state() if torch.backends.mps.is_available() else Noneに書き換える。torch.cuda.set_rng_state(cuda_rng_state)をtorch.set_rng_state(cuda_rng_state)に書き換える。torch.cuda.manual_seed(seed)を#torch.cuda.manual_seed(seed)に書き換えてコメントアウトする。torch.cuda.seed()を#torch.cuda.seed()に書き換えてコメントアウトする。
また、以下の部分も書き換える。
with torch.cuda.device(torch.cuda.current_device()):
torch.cuda.empty_cache()の部分を
with torch.device("mps" if torch.backends.mps.is_available() else "cpu"):
torch.mps.empty_cache()に書き換える。
古いバージョンの学習方法
kohya_gui.pyを使いたいが、UI周りのエラーが出て解消する気力がなかったので、とりあえずCUIを使う。
(コピペしてzsh: no such file or directoryが出たら\の後ろに余分な空白が無いか確認する)
accelerate launch --num_cpu_threads_per_process 4 train_network.py \
--pretrained_model_name_or_path="your_base_model_path/model_name.safetensors" \
--train_data_dir="kohya_ss/data/train" \
--reg_data_dir="kohya_ss/data/reg" \
--prior_loss_weight=1.0 --resolution 512 \
--output_dir="kohya_ss/data/outputs" \
--output_name=your_lora_name \
--train_batch_size=2 --learning_rate=1e-4 --max_train_epochs 4 \
--seed 42 --save_model_as=safetensors --save_every_n_epochs=1 \
--max_data_loader_n_workers=1 \
--network_module=networks.lora --network_dim=4 \
--training_comment="activate by pochi dog" \
--enable_bucket --bucket_no_upscale \
--optimizer_type="AdamW" --mixed_precision="no" --save_precision="float"- –pretrained_model_name_or_path:学習元のモデルへのパス
- –train_data_dir:学習用ディレクトリへのパス(今回はtrainディレクトリ)
- –reg_data_dir:正規化用ディレクトリへのパス(今回はregディレクトリ)
- –max_train_epochs:エポック数
- –output_name:LoRAの名前(自由)
- –enable_bucket –bucket_no_upscale:学習に使う画像が大きすぎると怒られるので設定した
- –train_batch_size:ミニバッチサイズ(メモリに合わせて変更する)
- –optimizer_type:オプティマイザーとか好きなのを使いたいなら変更する
上記の引数はとりあえず動くように調整したものなので、学習を効率的に行うには要調整。
ただし、fp16とかAdamW8bitとかを使おうとすると多分動かないので注意。
また、実行環境がM1Max(64GB)なのでメモリ周りは調整が必要かも…
その他、引数については配布元のページを参照すること。
https://github.com/kohya-ss/sd-scripts/blob/main/train_README-ja.md
https://github.com/kohya-ss/sd-scripts/blob/main/train_network_README-ja.md
学習時に途中経過のサンプル画像を生成したい場合
学習を開始するコマンドに引数を追加する
--sample_every_n_epochs=1 \
--sample_sampler="k_euler_a" \
--sample_prompts="kohya_ss/data/prompt.txt"生成用のプロンプトをテキストファイルに保存しておく。
# prompt 1
pochi, run --w 512 --h 512 --d 1 --l 7.5 --s 20生成用のコードがcuda用なので、kohya_ss/library/train_util.py内にあるcudaと書かれている部分をmpsに書き換えてmps用に改変する。(テキストエディタの置換であっさりと通った)
変更箇所の詳細
以下の箇所を変更しました。
① 2939行目

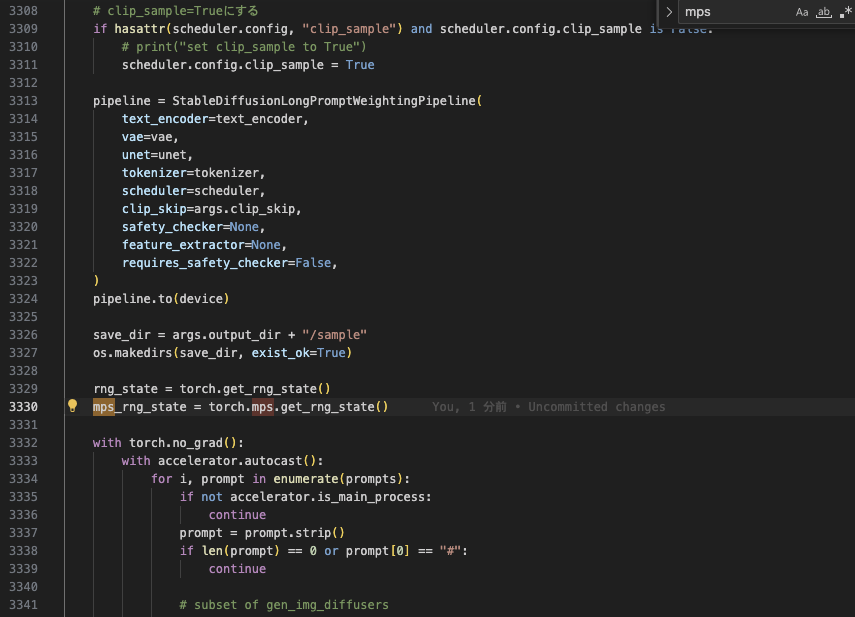
② 3330行目
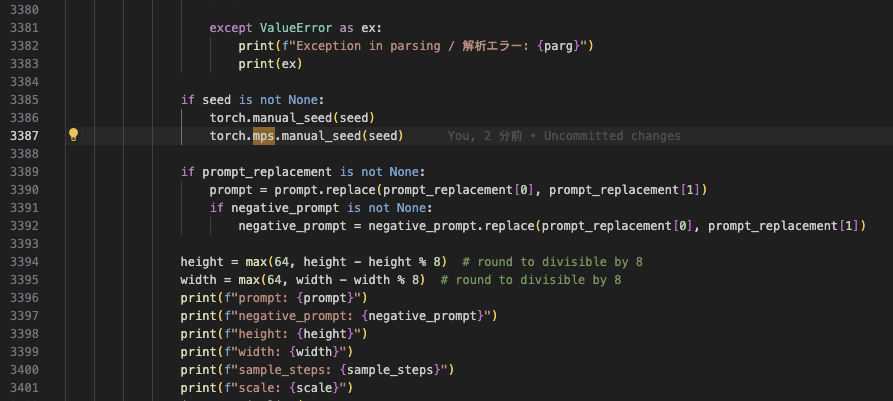
③ 3387行目
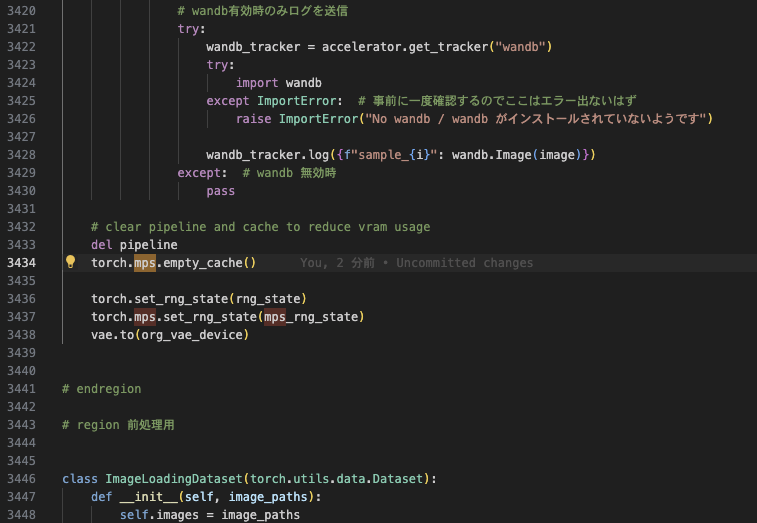
④ 3434行目・3437行目
ただし、ダウンロードしたコードのバージョンによってはうまくいかない可能性があります。
ちなみに、筆者の環境でダウンロードしているkohya_ssレポジトリのコミットのハッシュは 52dd50fb91841ecdbb3c7b89df3ca9944ec00216 です。
その場合は、最新のコードに合わせて修正するか、以下のように筆者の環境とバージョンを揃えてコードを修正してみてください。
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
git branch test_branch 52dd50fb91841ecdbb3c7b89df3ca9944ec00216
git checkout test_branchPytorchバージョンの注意
Pytorch1.13.0前後のバージョンを使用していると、LossがNaNになるというバグがある。
https://github.com/pytorch/pytorch/issues/88331
現在は修正されているので、アップグレードする。
pip3 install -U torch torchvision torchaudio学習したLoRAを使用する
学習したモデルはoutput_dirで指定したディレクトリ(ここではkohya_ss/outputs/20_dogs)に保存されている。
あとは、web-uiなどを使って普通にLoRAを使用すればよい。